
Nagy táblázatokat is olvasnak a nagy nyelvmodellek
A nagy nyelvmodellek (LLM) kis táblázatokat feldolgoznak, de nagyobbakkal meggyűlik a bajuk, mert túl méretes az input.
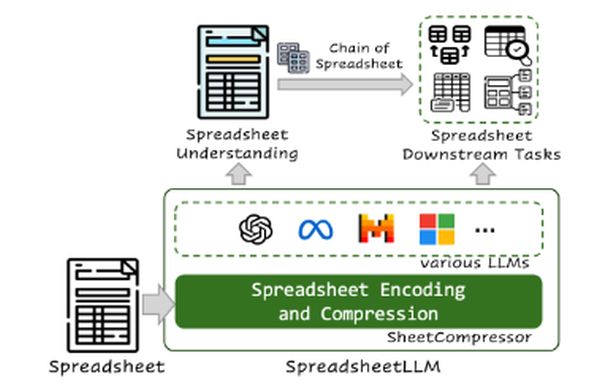
A Microsoft kutatói táblázattömörítő megoldást javasolnak, így LLM-ek is képesek azonosítani azokat, vizsgálhatják speciális kérdéseket megválaszoló részeiket.
A legtöbb táblázat kisebb táblázatok készletére bontható. Ezeket vizuális elválasztók, például vastag vonalak, üres sorok és/vagy oszlopok határolhatják. Mivel ugyanazokat a markertípusokat tartalmazhatják, a kisebb egységek észlelése azonban nem triviális.
Sok kérdés megválaszolásához nincs szükség a teljes táblázatra, csak a megfelelő részre, a táblázaton belüli valamelyik kisebb táblázatra. Az LLM-nek azonban a bemenethez (input kontextusablakhoz) esetleg túl nagy teljeset kell látnia először, és elemeznie kell az egymástól nem egyértelműen elkülönülő kisebb táblázatokat.

A táblázat tömörítése a megoldás. A tömörített reprezentációt és a kérdést betáplálják az LLM-be, valamint azt az utasítást kapja, hogy azonosítsa a szükséges kisebb táblázat határait. Miután ez megtörtént, a nyelvmodell a tömörítetlen változat alapján képes megválaszolni a kérdést.
A kutatók a táblázatot kisebb táblázatokra szétszedő, azokat tömörítő, de az eredeti szerkezetet megtartó szoftvert fejlesztettek. Utána LLM-eket finomhangoltak, hogy a tömörített táblázatban detektáljon kisebbeket, majd szöveges utasításokat (promptokat) adtak nekik, hogy azonosítsa az adott kérdés szempontjából releváns kisebb táblázatokat.
A teszteknél változatos méretű, négyezer és tizenkétezer token közötti táblázatokat használtak. Tömörített kicsiknél a Llama 3 83, nagyobbaknál 62, a GPT-4 81 és 69 százalékot ért el. Nem tömörített kicsiknél a Llama 3 72, a GPT-4 69 százalékos pontossággal dolgozott, nem tömörített nagyokkal egyikük sem boldogult (0 százalék).
Kérdések megválaszolásában tömörítetteknél a GPT-4 74, nem tömörítetteknél 47 százalékos hatékonysággal teljesített.
0 Hozzászólás:
Legyél te az első hozzászóló!
Hozzászólás írásához be kell jelentkezni: