
Megmagyarázható lesz a nagy nyelvmodellek működése
A mai mesterségesintelligencia-fejlesztések alapja, a nagy nyelvmodellek (large language models, LLM) működése sok kérdést vet fel, mert nem értjük teljesen. Miként változtatja meg a modell finomhangolása a bemenetek megjelenítését? Mi történik a modell belsejében a gondolati láncra felépített promptolás során, és ez mennyiben különbözik a strukturálatlan promptolástól?
Ezek csak a legfontosabb kérdések. Ha viszont mindegyik réteghez begyakoroltatunk egy SAE-t (sparse autoencoder, ritka önkódoló), közelebb kerülünk a válaszokhoz.
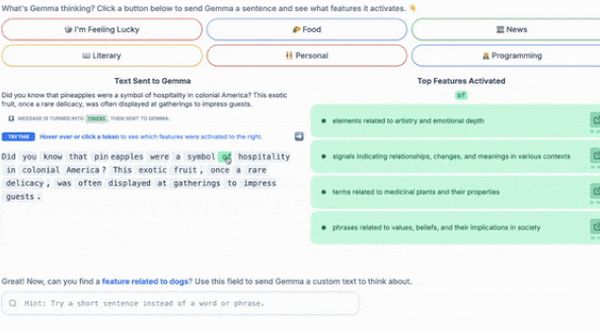
A Google kutatói ezért fejlesztették a Gemma Scope rendszert, amely világosabbá teszi, hogy a Gemma-2 nyelvmodell-családban a rétegek hogyan reagálnak input tokenekre. A Gemma 2 kilencmilliárd és a friss kétmilliárd paraméteres változatához is elérhető, interaktív demóval mi is tesztelhetjük.
Egy SAE saját bemeneti adatainak rekonstruálását megtanuló neurális háló.
Ha manapság látni szeretnénk, hogy egy hálóréteg mit tud az adott bemeneti tokenről, beadhatjuk neki a tokent, és tanulmányozhatjuk az általa generált beágyazást. Ezzel a megközelítéssel az a gond, hogy a beágyazás összes indexének értékei más értékekhez szintén társítható fogalmak szövevényét képviselhetik. Túl sok ahhoz, hogy nyomon tudjuk követni.
A SAE másként működik: a beágyazást úgy alakítja át, hogy minden egyes index külön fogalomnak felel meg. Képes megtanulni a beágyazás az értékek számánál sokkal nagyobb számú vektor súlyozott összegével történő ábrázolást. Mindegyik súlyozott összegnek kevés nullától eltérő súlya van, azaz minden beágyazás csak a SAE-vektorok kisszámú vagy ritka részhalmazaként jeleníthető meg. Mivel a betanított SAE-vektorok száma sokkal nagyobb az eredeti beágyazásban szereplő értékek számánál, minden adott vektor nagyobb valószínűséggel képvisel külön fogalmat, mint az eredeti beágyazás bármelyik értéke.
Ennek az összegnek a súlyai értelmezhetők. Mindegyik súly azt jelzi, hogy a kapcsolódó fogalom milyen erősen jelenik meg a bemenetben. Ha adott egy token, a SAE első rétege állítja elő ezeket a súlyokat.
A kutatók több mint négyszáz SAE-t, a Gemma 2 2B és 9B mindegyik rétegéhez egyet-egyet építettek. Az előzetes gyakorló adatkészletből tápláltak be példákat, majd rétegenként kivonatolták a beágyazásokat.
Az adott rétegből származó beágyazásokból a SAE megtanulta mindegyiket rekonstruálni. Speciális technikával minimálisra csökkentette az első réteg nullától eltérő kimeneteinek számát, biztosítva, hogy csak a beágyazáshoz kapcsolódó fogalmakat használjon. Az első réteg által létrehozott beágyazás értelmezéséhez a kutatók a megfelelő fogalmakkal címkézték a beágyazás-indexeket. Két módszert alkalmaztak: manuálist és automatikust.
0 Hozzászólás:
Legyél te az első hozzászóló!
Hozzászólás írásához be kell jelentkezni: