
Megjelent az első kínai szöveget videóvá alakító modell
Mérföldkőhöz érkezett a kínai Kuaishou vállalat: június hatodikán elindította az első nyilvánosan tesztelhető, szövegből videót ingyen generáló, jelenleg már hatszázmillió felhasználós mesterségesintelligencia-modellt. Neve Kling, és az OpenAI Sora MI-jéhez hasonlóan (elvileg) akár kétperces, másodpercenkénti 30 képkockás, maximum 1080p videófelbontású anyagokat hoz létre.
Sora sajnos négy hónap után is elérhetetlen a nyilvánosság számára…

Zeyi Yang, az MIT Technology Review China Reportjának állandó szerzője letesztelte, és arra a következtetésre jutott, hogy kizárólag angolul írt promptokat nem dolgoz fel, viszont a szöveget vagy lefordítjuk kínaira, vagy – és ez a könnyebb opció – beteszünk egy-két kínai szót, és Kling máris jól teljesít. (A képi illusztráción az angol eredetik, Yang promptjai és a végeredmények láthatók)
A képek Yang próbálkozásai. A tokiói utca és a cica válasz Sora nagyjából azonos promptjaira.
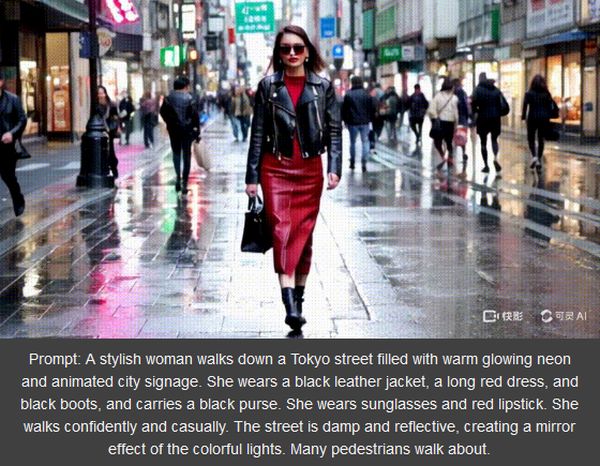
Klinggel kapcsolatban megállapította, hogy a videók alig térnek el a szöveges utasításoktól. A modellnek három percre van szüksége a válaszra. Nem a leggyorsabb, de abszolút elfogadható – állapította meg az újságíró.
Vannak hiányosságok is: a videók hiába 720p formátumúak, homályosak és szemcsések, Kling időnként figyelmen kívül hagyja a prompt fontos részleteit, és hiába ígérnek akár két percet, az összes mostani videó maximum öt másodperc, így értelemszerűen se nem túl dinamikusak, se nem elég komplexek. (Yang szerint a hosszabbak inkább hallucinációk, inkonzisztensek.)

Ugyanakkor nem korrekt Sora nyilvános demóknak szánt, tehát a legjobb anyagaival összehasonlítani ezeket az első próbálkozásokat.
A pekingi MI-művész, a modellt megjelenése óta tesztelő Guizang szerint Kling generatív képességei elég jók. Össze is válogatott egy gyűjteményt, hogy összehasonlítsa Soraval. Az utóbbi magasabb esztétikai kvalitást hoz létre, de Kling hátránya nem vészes. A fizikát és a valódi természetes környezeteket jól szimulálja – ezek a modellek legfontosabb képességei.

Működése is hasonló az OpenAI MI-jéhez: a videógenerálásban használt két diffúziós modellt transzformer architektúrával kombinál. Ez az architektúra garantálja nagyobb videófájlok értelmezését és a pontosabb outputokat.
Egy komoly előnye viszont van: sokkal nagyobb, kollektíven gyűjtött videó-adatbázisból válogathat. A tanulás minden szempontból megfelel a jogi és az iparági követelményeknek.
0 Hozzászólás:
Legyél te az első hozzászóló!
Hozzászólás írásához be kell jelentkezni: