
A világ leggyorsabb mesterségesintelligencia-platformja
A SambaNova Systems a Llama 3.1 405B (a B a milliárd paraméter rövidítése) modelljét a versenytársaknál jóval gyorsabban futtató felhőszámítás-szolgáltatást indított. Elérhető egy ingyenes és fizetős (vállalkozás) szint is, a szintén fizetős fejlesztői szint év végéig startol.
A vállalat szabadalmaztatott (SN40L) chipeket és szoftvert használva gyorsítja fel a modell következtetési folyamatát.
A Llama 3.1 405B másodpercenként 149 tokent képes generálni, jelenleg nincs is gyorsabb a piacon, ez a világcsúcs. A millió input/output token ára öt-tíz dollár. A 70B sebessége 461 token/másodperc.
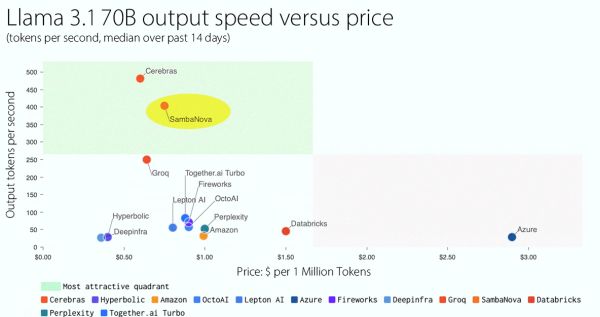
A Cerebras, egy másik felhőszolgáltató mögötti 70B változat másodpercenkénti 411 tokent hoz létre, az árak alacsonyabbak: 0,80 és 1,20 dollár között mozognak. A szintén Cerebras mögötti 8B 998 tokent teljesít, 0.10-0.30 dollár közötti áron. A gyorsaság és olcsóság a modellek méretének tudható be: jóval kisebbek, mint a SambaNova felhőjében működő 405B.
A SambaNova saját tesztjén a 405 B 132, a 70B 461 token/másodperc tempót ért el. Sok versenytárssal ellentétben, a Llama 3.1-et 16-bites pontossággal futtatja (ami szintén világcsúcs). A kevésbé pontos feldolgozást végző modellek ugyan gyorsabbak és alacsonyabb a fogyasztásuk, de eredményeik is rosszabbak. A SambaNova kontextus-ablaka azonban nagyon korlátozott, mindössze nyolcezer token a natív 120 ezerrel szemben.
Az új szolgáltatást óriási verseny közepette vezették be, a számítási felhő és az MI használatban érintett, szintén saját speciális chippel dolgozó összes rivális fel akarja gyorsítani a következtetést. A Cerebras és a Groq is nagyon gyors következtetés-szolgáltatást vezetett be.
Az eredmény, a költségek, a teljesítmény és a késleltetés MI-modellek gyakorlati alkalmazásának kritikus tényezői. A gyorsaság elősegíti az ágens-munkamenetet és a valósidejű döntéshozást.
Nyitott súlyokkal dolgozó modelleket ma már gyorsabban szolgálnak ki, mint a hasonló teljesítményű szabadalmaztatottakat. Ez tovább ösztönözheti a nyílt modellek és a nagyszámú kimeneti tokent igénylő promptolás stratégiák terjedését.
0 Hozzászólás:
Legyél te az első hozzászóló!
Hozzászólás írásához be kell jelentkezni: