
A „peremen” futó mesterségesintelligencia-alkalmazások drasztikus növekedése várható
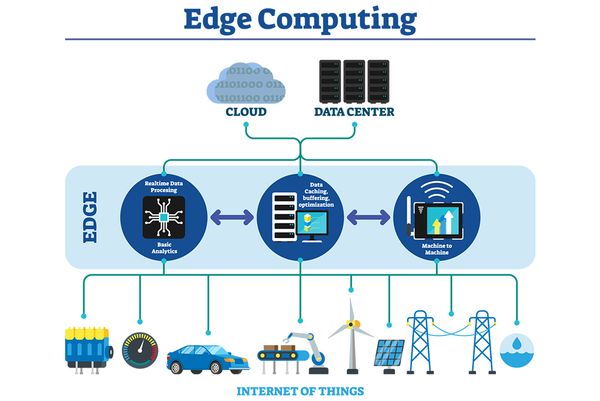
Előrejelzések alapján 2025-ig 61 százalékkal nő a világ adatállománya (a céges adatoké 75 százalékkal). A növekedés jelentős részben a hálózatok peremén (edge) ténykedő, irdatlan mennyiségű adatot generáló dolgok internetével (IoT) magyarázható. Minden adatot a számítási felhőben lévő adatközpontok tárolnak, dolgoznak fel, amivel a hálózati sávszélesség-követelmények drasztikusan növekednek, és a lehetőségek határát közelítik. Hiába fejlődik a technológia, az adatközpontok nem garantálják a sok alkalmazás szempontjából kritikus megfelelő átviteli sebességet és válaszidőt. Ráadásul a peremen működő eszközök (IoT, okostelefonok, laptopok, PC-k) folyamatosan használják a felhőből jövő adatokat.
Andrew Ng világhírű gépitanulás-szakértő szerint a mesterséges intelligencia, benne a generatív MI is gyorsan terjed a hálózatok peremén futó alkalmazásokban. Észrevétele ellentmondani látszik a hagyományosan értelmezett számítástudománynak: a legtöbb MI adatközpontokban, és nem peremeszközökön fut.
Több okból: a legmasszívabb nagy nyelvmodellek (LLM-ek) legalább százmilliárd vagy több paraméteresek, és még a következtetésekhez is óriási memóriakapacitás szükséges.
Az üzleti vállalkozások a felhőszámítás-alapú, „szoftver, mint szolgáltatás” (SaaS) termékeket jobban szeretik a peremen futó szoftvereknél. Az SaaS-szel a cégek hozzáférnek a termék minőségén javító adatokhoz, és könnyebb is vele a frissítés.
A legtöbb mai fejlesztőt SaaS-alkalmazások építésére gyakoroltatták, és inkább írnak felhőalapú, mint desktop- vagy más edge-alkalmazást.

Ng szerint mégis óriási a potenciál a perem és az MI összekapcsolódásában. Például azért, mert az MI-alkalmazások egyre jobban működnek peremeszközökön. Laptopján rendszeresen futtat egy-tízmilliárd paraméteres modelleket, ha pedig repülőn, wifi nélkül dolgozik, kis modelleket használ.
Sok alkalmazás esetében nincs semmi probléma korlátozott méretű modellekkel, mindegyik finomhangolható az aktuális feladathoz. Nyelvtani hibák kijavításához egyébként sem kell a történelemről, filozófiáról, csillagászatról és minden más témáról átfogó ismerettel rendelkező, 175 milliárd paraméteres modell.
Sok felhasználó, különösen az 1996 és 2010 között született Z-generáció – a jövőbeli trendek indikátora – egyre érzékenyebb a személyes adatokra (privacy), és ha például a helyesírási hibáinkat ellenőrizzük, semmi szükségünk adatainkat nagy techcégekkel megosztani. De az adataik magántermészetét féltő cégek számára is vonzó lehet az edge computing.
Erős kereskedelmi érdekek szintén a perem felé terelik az MI-t. A chipfejlesztők, mint például az Nvidia, az AMD és az Intel adatközpontoknak és PC-s, laptopos használatra értékesítik a chipeket. Így a félvezető- és a PC/laptop-gyártók erősen motiváltak a „perem MI” (edge AI) elterjedésében, mivel fogyasztóiknak a modernebb MI-használathoz frissíteniük kell a gépeiket. Magyarán sok cég kezd profitálni a perem MI felemelkedéséből, és komoly érdekük a reklámozása.
0 Hozzászólás:
Legyél te az első hozzászóló!
Hozzászólás írásához be kell jelentkezni: